Applies To:
Show Versions
BIG-IP AAM
- 11.6.5, 11.6.4, 11.6.3, 11.6.2, 11.6.1
Overview: Introduction to acceleration
BIG-IP acceleration, deployed symmetrically, asymmetrically, or in combination, can significantly improve transaction response times. It includes specific techniques that modify or optimize the way in which TCP and other protocols, applications, and data flows can function across the network. Acceleration features enable you to refine transaction response times, according to your specific needs.
| Acceleration feature | Benefit |
|---|---|
| Origin web server load balancing | Enables users to access the best-performing source. |
| Global server load balancing | Enables users to access the best-performing site. |
| Compression | Reduces the amount of transmitted data. Asymmetric compression condenses web data for transmission to a browser. Symmetric compression condenses any data transmission to a remote acceleration device. |
| Data deduplication | Replaces previously sent data with dictionary pointers to minimize transmitted data and improve response time. Also ensures that the data is current and delivered only to authorized users. This feature is available only with a licensed BIG-IP device. |
| TCP optimization | Improves TCP performance. Asymmetric optimization aggregates requests for any TCP protocol to reduce connection processing. It optimizes TCP processing for TCP/IP stacks that increase client-side connections to speed web page downloads. Symmetric optimization aggregates transactions inside tunnels that connect acceleration devices. |
| Web browser object caching | Manipulates HTTP responses to increase browser caching and decrease HTTP requests. |
| Remote web object caching | Reduces client response times by serving web objects directly from a remote device, rather than from a central server. |
| HTTP protocol and web application optimization | Manipulates web requests and responses to increase HTTP and web application efficiency. |
Origin web server load balancing
A virtual IP address can be configured on a BIG-IP Local Traffic Manager, which then acts as a proxy for that IP address. The BIG-IP Local Traffic Manager directs a client request made to the VIP to a server among a pool of servers, all of which are configured to respond to requests made to that address. A server pool improves the response time by reducing the load on each server and, consequently, the time required to process a request.
About data centers
All of the resources on your network are associated with a data center. BIG-IP Global Traffic Manager (GTM) consolidates the paths and metrics data collected from the servers, virtual servers, and links in the data center. GTM uses that data to conduct load balancing and route client requests to the best-performing resource based on different factors.
GTM might send all requests to one data center when another data center is down. Alternatively, GTM might send a request to the data center that has the fastest response time. A third option might be for GTM to send a request to the data center that is located closest to the client's source address.
Data compression
Compression of HTTP and HTTPS traffic removes repetitive data and reduces the amount of data transmitted. Compression provided by the Local Traffic Manager offloads the compression overhead from origin web servers and allows the Local Traffic Manager to perform other optimizations that improve performance for an HTTP or HTTPS stream.
Data deduplication
Data deduplication requires the symmetric acceleration provided by BIG-IP Application Acceleration Manager (AAM). A client-side device sends a request to a server-side device, The server-side device responds to the client object request by sending new data and a dictionary entry or pointer that refers to the data to the client-side device. The client-side device stores the data and the pointer before sending it on to the requesting client. When a user requests the data a second or subsequent time from the client-side device, the server-side device checks for changes to the data, and then sends one or more pointers and any new data that has not been previously sent.
Optimization of TCP connections
The BIG-IP application acceleration provides MultiConnect functionality that decreases the number of server-side TCP connections required while increasing the number of simultaneous client-side TCP connections available to a browser for downloading a web page.
Decreasing the number of server-side TCP connections can improve application performance and reduce the number of servers required to host an application. Creating and closing a TCP connection requires significant overhead, so as the number of open server connections increases, maintaining those connections while simultaneously opening new connections can severely degrade server performance and user response time.
Despite the ability for multiple transactions to occur within a single TCP connection, a connection is typically between one client and one server. A connection normally closes either when a server reaches a defined transaction limit or when a client has transferred all of the files that are needed from that server. The BIG-IP system, however, operates as a proxy and can pool TCP server-side connections by combining many separate transactions, potentially from multiple users, through fewer TCP connections. The BIG-IP system opens new server-side connections only when necessary, thus reusing existing connections for requests from other users whenever possible.
The Enable MultiConnect To check box on the Assembly screen of BIG-IP applies MultiConnect functionality to image or script objects that match the node. The Enable MultiConnect Within check box, however, applies MultiConnect functionality to image or script objects that are linked within HTML or CSS files for the node.
Caching objects
Caching provides storage of data within close proximity of the user and permits reuse of that data during subsequent requests.
Web browser objects
In one form of caching, a BIG-IP instructs a client browser to cache an object, marked as static, for a specified period. During this period, the browser reads the object from cache when building a web page until the content expires, whereupon the client reloads the content. This form of caching enables the browser to use its own cache instead of expending time and bandwidth by accessing data from a central site.
Remote web objects
In a second form of caching, a BIG-IP in a data center manages requests for web application content from origin web servers. Operating asymmetrically, the BIG-IP caches objects from origin web servers and delivers them directly to clients. The BIG-IP module handles both static content and dynamic content, by processing HTTP responses, including objects referenced in the response, and then sending the included objects as a single object to the browser. This form of caching reduces server TCP and application processing, improves web page loading time, and reduces the need to regularly expand the number of web servers required to service an application.
Non-web objects
In a third form of caching, a BIG-IP at a remote site, operating symmetrically, caches and serves content to users. The BIG-IP serves content locally whenever possible, thus reducing the response time and use of the network.
Optimization of HTTP protocol and web applications
HTTP protocol optimization achieves a high user performance level by optimally modifying each HTTP session. Some web applications, for example, cannot return an HTTP 304 status code (Not Modified) in response to a client request, consequently returning an object. Because the BIG-IP proxies connections and caches content, when a requested object is unchanged, the BIG-IP returns an HTTP 304 response instead of returning the unchanged object, thus enabling the browser to load the content from its own cache even when a web application hard codes a request to resend the object.
The BIG-IP improves the performance of Web applications by modifying server responses, which includes marking an object as cacheable with a realistic expiration date. This optimization is especially beneficial when using off-the-shelf or custom applications that impede or prevent changes to code.
Overview: BIG-IP Acceleration
The BIG-IP provides an acceleration delivery solution designed to improve the speed at which users access your web applications (such as Microsoft SharePoint, Microsoft Outlook Web Access, BEA AquaLogic, SAP Portal, Oracle Siebel CRM, Oracle Portal, and others) and wide area network (WAN).
The BIG-IP accelerates access to your web applications by using acceleration policy features that modify web browser behavior, as well as compress and cache dynamic and static content, decreasing bandwidth usage and ensuring that your users receive the most expedient and efficient access to your web applications and WAN.
Application management
To accelerate and manage access to your applications, the BIG-IP system uses acceleration policies to manipulate HTTP responses from origin web servers. After the BIG-IP system manipulates the HTTP responses, it processes the responses. Therefore, the BIG-IP system processes manipulated responses, rather than the original responses that are sent by the origin web servers.
Application monitoring
You can easily monitor your HTTP traffic and system processes by using various monitoring tools. You can use BIG-IP application acceleration performance reports, the BIG-IP Dashboard, and other related statistics or logging, as necessary to acquire the information that you want.
Deployment of Distributed BIG-IP Application Acceleration
You can deploy BIG-IP application acceleration functionality to optimize HTTP traffic in a worldwide, geographically distributed configuration.
A geographically distributed deployment consists of two or more BIG-IP devices installed on each end of a WAN: one in the same location as the origin web servers that are running the applications to which the BIG-IP is accelerating client access, and the other near the clients initiating the requests.
Deploying multiple BIG-IP devices achieves additional flexibility in controlling where processing takes place. To prevent sending assembled documents over the WAN, all assembly, except PDF and image optimization, occurs on the device that resides closest to the initiated request.
Management of requests to origin web servers
Most sites are built on a collection of web servers, application servers, and database servers, together known as origin web servers. The BIG-IP system is installed on your network between the users of your applications and the origin web servers on which the applications run, and accelerates your application’s response to HTTP requests.
Origin web servers can serve all possible permutations of content, while the BIG-IP system only stores and serves page content that clients have previously requested from your site. By transparently servicing the bulk of common requests, the BIG-IP system significantly reduces the load on your origin web servers, which improves performance for your site.
Once installed, the BIG-IP system receives all requests destined for the origin web server. When a client makes an initial request for a specific object, the BIG-IP system relays the request to the origin web server, and caches the response that it receives in accordance with the policy, before forwarding the response to the client. The next time a client requests the same object, the BIG-IP system serves the response from cache, based on lifetime settings within the policy, instead of sending the request to the origin web servers.
For each HTTP request that the BIG-IP system receives, the system performs one of the following actions.
| Action | Description |
|---|---|
| Services the request from its cache | Upon receiving a request from a browser or web client, the BIG-IP system initially checks to see if it can service the request from compiled responses in the system’s cache. |
| Sends the request to the origin web servers | If the BIG-IP system is unable to service the request from the system’s cache, it sends a request to the origin web server. Once it receives a response from the origin web server, the BIG-IP system caches that response according to the associated acceleration policy rules, and then forwards the request to the client. |
| Relays the request to the origin web servers | The BIG-IP system relays requests directly to the origin web server, for some predefined types of content, such as requests for streaming video. |
| Creates a tunnel to send the request to the origin web servers | For any encrypted traffic (HTTPS) content that you do not want the BIG-IP system to process, you can use tunneling. Note that the BIG-IP system can cache and respond to SSL traffic without using tunnels. |
During the process of application matching, the BIG-IP system uses the hostname in the HTTP request to match the request to an application profile that you created. Once matched to an application profile, the BIG-IP system applies the associated acceleration policy’s matching rules in order to group the request and response to a specific leaf node on the Policy Tree. The BIG-IP system then applies the acceleration policy’s acceleration rules to each group. These acceleration rules dictate how the BIG-IP system manages the request.
Management of responses to clients
The first time that a BIG-IP system receives new content from the origin web server in response to an HTTP request, it completes the following actions, before returning the requested object (response) to the client.
| Action | Description |
|---|---|
| Compiles an internal representation of the object | The BIG-IP system uses compiled responses received from the origin web server, to assemble an object in response to an HTTP request. |
| Assigns a Unique Content Identifier (UCI) to the compiled response, based on elements present in the request | The origin web server generates specific responses based on certain elements in the request, such as the URI and query parameters. The BIG-IP system includes these elements in a UCI that it creates, so that it can easily match future requests to the correct content in its cache. The BIG-IP system matches content to the UCI for both the request and the compiled response that it created to service the request. |
Flow of requests and responses
The BIG-IP system processes application requests and responses in a general sequential pattern.
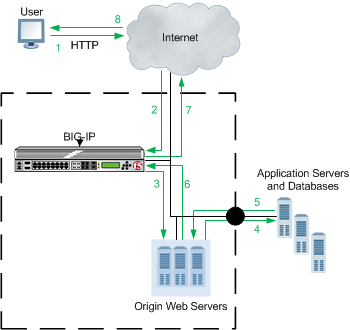
Each step is processed in the following sequence.
- Clients, using web browsers, request pages from your site. From the client’s perspective, they are connecting directly to your site; they have no knowledge of the BIG-IP system.
- The BIG-IP system examines the client’s request to determine if it meets all the HTTP requirements needed to service the request. If the request does not meet the HTTP requirements, the BIG-IP system issues an error to the client.
- The BIG-IP system examines the request elements and creates a UCI, and then reviews the
system’s cache to see if it has a compiled response stored under that same UCI.
If the content is being requested for the first time (there is no matching compiled response in the system’s cache), the BIG-IP system uses the host map to relay the request to the appropriate origin web server to get the required content.
If content with the same UCI is already stored as a compiled response in the system’s cache, the BIG-IP system checks to see if the content has expired. If the content has expired, the BIG-IP system checks to see if the information in the system’s cache still matches the origin web server. If it does, the BIG-IP system moves directly to step 7. Otherwise, it performs the following step.
- The origin web server either responds or queries the application servers or databases content.
- The application servers or databases provide the input back to the origin web server.
- The origin web server replies to the BIG-IP system with the requested material, and the BIG-IP system compiles the response. If the response meets the appropriate requirements, the BIG-IP system stores the compiled response in the system’s cache under the appropriate UCI.
- The BIG-IP system uses the compiled response, and any associated assembly rule parameters, to recreate the page. The assembly rule parameters dictate how to update the page with generated content.
- The BIG-IP system directs the response to the client.
About symmetric optimization using iSession on BIG-IP systems
The BIG-IP systems work in pairs on opposite sides of the WAN to optimize the traffic that flows between them through an iSession connection. A simple point-to-point configuration might include BIG-IP systems in data centers on opposite sides of the WAN. Other configuration possibilities include point-to-multipoint (also called hub and spoke) and mesh deployments.
The following illustration shows an example of the flow of traffic across the WAN through a pair of BIG-IP devices. In this example, traffic can be initiated on both sides of the WAN.
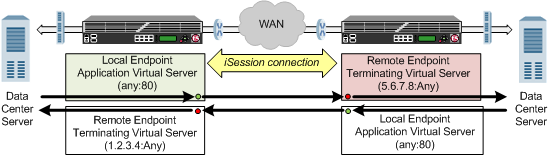 Example of traffic flow through a BIG-IP pair with iSession connection
Example of traffic flow through a BIG-IP pair with iSession connection
Each BIG-IP device is an endpoint. From the standpoint of each BIG-IP device, it is the local endpoint. Any BIG-IP device with which the local endpoint interacts is a remote endpoint. After you identify the endpoints, communication between the BIG-IP pair takes place in an iSession connection between the two devices. When you configure the local BIG-IP device, you also identify any advertised routes, which are subnets that can be reached through the local endpoint. When viewed on a remote system, these subnets appear as remote advertised routes.
To optimize traffic, you create iApps templates to select the applications you want to optimize, and the BIG-IP system sets up the necessary virtual servers and associated profiles. The system creates a virtual server on the initiating side of the WAN, with which it associates a profile that listens for TCP traffic of a particular type (HTTP, CIFS, FTP). The local BIG-IP system also creates a virtual server, called an iSession listener, to receive traffic from the other side of the WAN, and it associates a profile that terminates the iSession connection and forwards the traffic to its destination. For some applications, the system creates an additional virtual server to further process the application traffic.
The default iSession profile, which the system applies to application optimization, includes symmetric adaptive compression and symmetric data deduplication.




